[주식-프로그래밍] 2. 크롤링 환경 구축 및 예제 따라하기 - Wikipedia
안녕하세요.
지난 글에 이어서 시작하겠습니다.
https://kang-stock-coding.tistory.com/12
파이썬의 기능을 사용하려면 '라이브러리'가 필요합니다.
여기서 라이브러리라고 한다면 쉽게 생각하면 프로그램이라고 생각하면 됩니다. 응?? 파이썬도 프로그램이 아닌가??
파이썬 = 윈도우
라이브러리 =프로그램 (예, 크롤링용 라이브러리 = 뷰티플수프, 데이터분석용 라이브러리 = 판다스)
그럼 크롤링 무작정해보겠습니다.
크롤링을 하기 위해서 'Beautiful Soup'(뷰티플 수프)라는 라이브러리가 필요합니다.
'구X'에서 검색하면 바로 나옵니다.

Beautiful Soup is a Python package for parsing HTML and XML documents (including having malformed markup, i.e. non-closed tags, so named after tag soup). It creates a parse tree for parsed pages that can be used to extract data from HTML[2], which is useful for web scraping
뷰티플수프는 Web scraping에 가장 잘 사용되는 Package 입니다. 여기서 Web scraping은 크롤링과 똑같은 말입니다.
wikepdia를 클릭해서 이동하면

아래와 같이 확인 가능하고요. Code example를 바로 복사해서 붙여 넣겠습니다.

Code Example을 복사해서 index.py에 붙여 넣어 줍니다. 그리고 저장(Ctrl+S)을 합니다.

그리고 일단 실행을 해보겠습니다.
똑같이 'python index.py'를 입력해도 되고, 이미 입력을 했다면 키보드 ↑ 화살표를 누르면 됩니다.
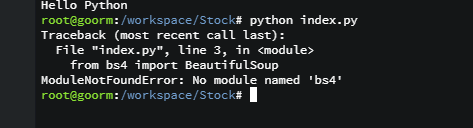
띠용??? 에러가 뜹니다. "모듈 낫 파운드 에러" bs4라는 모듈이 없다고 합니다.
from bs4 import BeautifulSoup from urllib.request import urlopen with urlopen('https://en.wikipedia.org/wiki/Main_Page') as response: soup = BeautifulSoup(response, 'html.parser') for anchor in soup.find_all('a'): print(anchor.get('href', '/'))
첫줄 코드내용이 bs4를 가져오는 내용인데, 'beautiful soup 4' 버젼이 설치되어 있지 않아서 생긴 에러입니다.
from bs4 import BeautifulSoup
그럼 설치를 해야겠죠. 설치는 간단하게 됩니다.
3번 화면인 명령어 입력창에 'pip install bs4'를 입력하면 자동으로 다운받고 설치까지 합니다.
바로 설치가 되는 경우도 있겠지만, 아래와 같이 WARNING이 뜰수도 있습니다. 내용을 보면, upgrade하라고 합니다.
"지금 쓰는 pip버젼이 19.3.1인데, 20.1.1로 업그레이드 해라"

'pip install --install pip'를 입력해줍니다.
그러면 아래와 같이 깔끔하게 19.3.1버젼을 언인스톨하고 20.1.1버젼을 인스톨 합니다.

다시 'pip instaal bs4'를 입력해주면 이미 설치 되어 있다고 합니다. 즉, 다시 입력해줄 필요는 없답니다^^

자 이제 설치가 다 되었으니, 실행을 해봐야 겠죠
실행방법은?? python index.py를 입력하던가 키보드 위방향 화살표를 누르다보면 이전 입력했던 명령어를 찾을수가 있습니다.

띠용~! 뭐라뭐라 엄청 많이 떳네요!!!
즉, wikipedia예제코드에 따라서 크롤링을 해왔습니다.
en.wikipedia.org/wiki/Main_Page')
with urlopen('https://en.wikipedia.org/wiki/Main_Page') as response:
soup = BeautifulSoup(response, 'html.parser')
for anchor in soup.find_all('a'):
print(anchor.get('href', '/'))
한줄 한줄 이제 읽어 보겠습니다.
with urlopen('https://en.wikipedia.org/wiki/Main_Page') as response:해당 웹사이트를 열어서 'response'에 담습니다.
위코드를 수정을 할수도 있습니다.
response = urlopen('https://en.wikipedia.org/wiki/Main_Page')이렇게 직관적으로 볼수 있게 바꿔 사용할수도 있습니다.
soup = BeautifulSoup(response, 'html.parser')설치한 Beautifulsoup을 이용해서 response를 넣어주고, html.parser를 이용하여 분석합니다.
이를 soup라는 변수에 담아줍니다.
for anchor in soup.find_all('a'):자 이제 반복문의 시작입니다.
soup.find_all('a'): soup변수에서 모든 'a'태그를 찾아서 anchor라는 변수에 넣습니다.
html에서 a태그는 링크를 의미합니다.
print(anchor.get('href', '/'))그리고 그렇게 가져온 anchor중에서 get('href') 즉 주소(여기서 a태그의 href는 주소입니다.)를 가져와서 프린트 해라.
그럼 코드가 어떻게 작동하는지 한번 봐야겠죠.
이제 실제 사이트로 들어가서 F12를 눌러서 개발자도구화면으로 들어 갑니다.
https://en.wikipedia.org/wiki/Main_Page

자그럼 a태그(링크)에서 href부분을 출력하는 코드가 바로 아래 반복문이 되는 것입니다.
for anchor in soup.find_all('a'): print(anchor.get('href', '/'))
이제 정말 걸음마를 시작한 단계입니다.
다음에는 실제 예제를 통해 크롤링을 해보겠습니다.
감사합니다.